
LLVM--#
Introduction to LLVM--#
LLVM-- is a subset of the LLVM intermediate representation.
Our subset is heavily based on LLVMlite developed at the University of Pennsylvania, but is further customized to the specifics of the Compilation course at Aarhus University.
This document outlines the structure of programs in the LLVM-- intermediate representation.
A minimal LLVM-- program#
The following is an example of a small LLVM-- program that returns number 42 as its result.
define i64 @main () {
ret i64 42
}
This program can be compiled, executed, and inspected for the return value using the following sequence of shell commands.
$ clang program.ll
$ ./a.out
$ echo $?
42
Here, clang invokes the LLVM compiler, assuming that the source file is program.ll.
Because we do not specify any options to clang, the compiler uses the default name a.out for the generated executable.
After invoking the executable, the OS stores its return value in the $? shell variable, and we print out the exit code using the echo shell command.[1]
Identifiers#
LLVM-- differentiates between two kinds of identifiers: global and local.
Global identifiers start with the @ symbol and are used for the definitions of global data definitions and functions.
Identifiers that start with the % symbol are used for the names of registers, named type definitions (see below), and for referring to the labels in branch instructions.
LLVM registers, e.g., %x, %y are local to each function.
There is no limit on the number of registers in a function.
On implicit registers in full LLVM
Note that full LLVM supports implicit register naming scheme (%0, %1, …) for function arguments and labels.
Our subset requires all arguments and labels to be explicitly named.
Types#
LLVM is a typed intermediate language.
In our subset, we distinguish between single value types, such as integers and pointers, and aggregate types, such as structures and arrays.
Additionally, we can define named types.
Finally, we distinguish a special void type used in function declarations.
Single value types#
Single value types include integers and pointers.
Integer types These are
i1,i8,i32,i64. The number after theisymbol corresponds to the number of bits. For example,i1is used for booleans,i8is used for characters, andi64is used for 64-bit integers. Note thatLLVM--does not use 32-bit integers (with the exception of indexing into structs via GEP).Pointer types All pointers, regardless of what they point to, have the same type
ptrin LLVM.
Aggregate types#
Aggregate types include structures and statically-sized arrays.
Structure types A structure type resembles record types in languages such as C. The syntax for the structure types is
{ t1, ..., tk }where each oft1…tkis a type. For example, the following is a structure consisting of three types{i1, ptr, i8}. Structure types may appear nested within structure types, for example{i1, {i64, ptr}},{i64, {i8, ptr, i64}, i1}.Statically-sized array types The syntax for array types is
[n x t], wherenis an integer indicating the static size of the array, andtis the array base type. For example, the type of an array with base typei64of size 10 is defined as[10 x i64]. Array base types can include other types, including structure and array types.
Named types#
Named types allow creating an abbreviation to other types.
The identifiers used in the type definitions need to start with % symbol; the named type definition moreover needs to use a designated type keyword.
The following example declares tuple to be a structure of two 64-bit integers.
%tuple = type {i64, i64}
Other named types may appear in named type definitions:
%tuplearray = type [10 x %tuple]
Note that our subset LLVM-- does not allow cycles in the declarations of named types.
Void type#
In addition to the types above, there is a special void type that is used in the declaration of the methods (cf. function header).
Its purpose is similar to the void type in languages such as C or Java.
On LLVM types that are not part of our subset
Note that full LLVM contains other primitive types such as floats, vectors, labels, and x86-mmx; we do not consider these in our subset, LLVM--.
Structure of LLVM-- Programs#
An LLVM-- program consists of three parts: global data definitions, named type definitions, and function definitions.
Global data definitions#
Global data definitions assign global identifiers to global constants.
Each global identifier starts with an @ character.
The syntax uses the global keyword.
An example of a global data definition is
@x = global i64 42
Here, @x is the name of the global identifier, i64 is the type of the definition and constant 42 is the value assigned to @x.
Global initializers Global initializers in LLVM are used to declare program constants. Similarly to types, global initializers may be simple and aggregate: Simple initializers include integers, e.g., 0, 1, 10, 42, or a null pointer constant. Aggregate initializers include structure initializers, e.g.,
{i64 0, {i64 1, i64 2}}, and static array initializers, e.g.,{i64 0, i64 1, i64 2}.String literals A common representation of string literals in LLVM is as arrays of type
i8. There is a shorthand syntax for declaring string literals, usingccharacter and the string in quotes:@s = global [5 x i8] c"Hello"
Note, however, that in our Dolphin compiler, there is some more work involved in the compilation of string literals and we use a slightly different representation.
Finally, note that a global data definition for type t produces a pointer (to type t).
Thus, the type of both @x and @s above is ptr.
Named type definitions#
The definitions of the named types uses the syntax explained in Named types. Several definitions of named types follow each other in a sequence.
%t1 = type ...
%t2 = type ...
%t3 = type ...
Declaring external functions#
External functions, e.g., functions implemented in the C runtime, can be called from LLVM if they are declared as external functions.
We use the declare keyword for declaring external functions as follows:
declare i64 @libfun (i64 %x)
In the above, the external function @libfun takes one argument, x of type i64, and returns an i64.
Function declarations#
Function declarations consist of a function header followed by a sequence of basic blocks in braces.
Function header#
Function header consists of the keyword define followed by the return type of the function, the function name, and the list of the typed argument identifiers in parentheses:
define i64 @foo (i64 %x, ptr %y, %sometype %z)
In the above, the function @foo takes three arguments: x of type i64, y of type ptr, and z of the named type %sometype.
Note the use of define keyword as opposed to declare keyword above used to declare external functions.
Basic blocks#
Basic blocks are the primary unit of control flow in LLVM--.
They consist of a sequence of LLVM instructions followed by a terminator.
The instructions in a basic block are always executed sequentially until the execution reaches the terminator.
The terminators include returning from a function, conditional and unconditional branching (jumps), and a special terminator indicating unreachable code (see below).
Branching instructions take the label of the target block as an argument.
This organization ensures that the execution cannot jump into a middle of a basic block via the branching instructions.
Instructions and terminators#
LLVM-- subset supports the following instructions:
Non-terminating instructions The following table lists the non-terminating instructions. Here, \(\mathit{binop}\) ranges over one of the
add,sub,mul,sdiv,srem,shl,lshr,ashr,and,or,xor, and the \(\mathit{comparator}\) argument to theicmpinstruction is one ofeq,ne,slt,sle,sgt,sge.
Name |
Description |
Example |
Returns a result |
|---|---|---|---|
\(\mathit{binop}\) |
binary operation on two operands |
|
Yes |
|
allocate memory on the current stack frame |
|
Yes |
|
load a value from memory |
|
Yes |
|
store a value in memory |
|
No |
|
compare values |
|
Yes |
|
call a function |
|
If non-void |
|
convert a pointer to an integer |
|
Yes |
|
compute address of a subelement in an aggregate |
see GEP below |
Yes |
|
compute result based on control-flow (see Phi nodes) |
|
yes |
Terminators A terminator is one of the following four instructions:
Description |
Example |
|---|---|
Conditional branch |
|
Unconditional branch |
|
Return with a return value |
|
Return w/o a return value |
|
End of basic block is unreachable |
|
The semantics of the conditional branch is that it jumps to the first label if the i1 value is 1 and the second label otherwise.
Example CFG: factorial function#
We consider a simple C function
int factorial(int X) {
if (X == 0) return 1;
return X*factorial(X-1);
}
Below is the LLVM code for this function (generated by clang) and the corresponding Control Flow Graph (CFG).
define i32 @factorial(i32) {
%2 = alloca i32
%3 = alloca i32
store i32 %0, ptr %3
%4 = load i32, ptr %3
%5 = icmp eq i32 %4, 0
br i1 %5, label %6, label %7
6:
store i32 1, ptr %2
br label %13
7:
%8 = load i32, ptr %3
%9 = load i32, ptr %3
%10 = sub nsw i32 %9, 1
%11 = call i32 @factorial(i32 %10)
%12 = mul nsw i32 %8, %11
store i32 %12, ptr %2
br label %13
13:
%14 = load i32, ptr %2
ret i32 %14
}
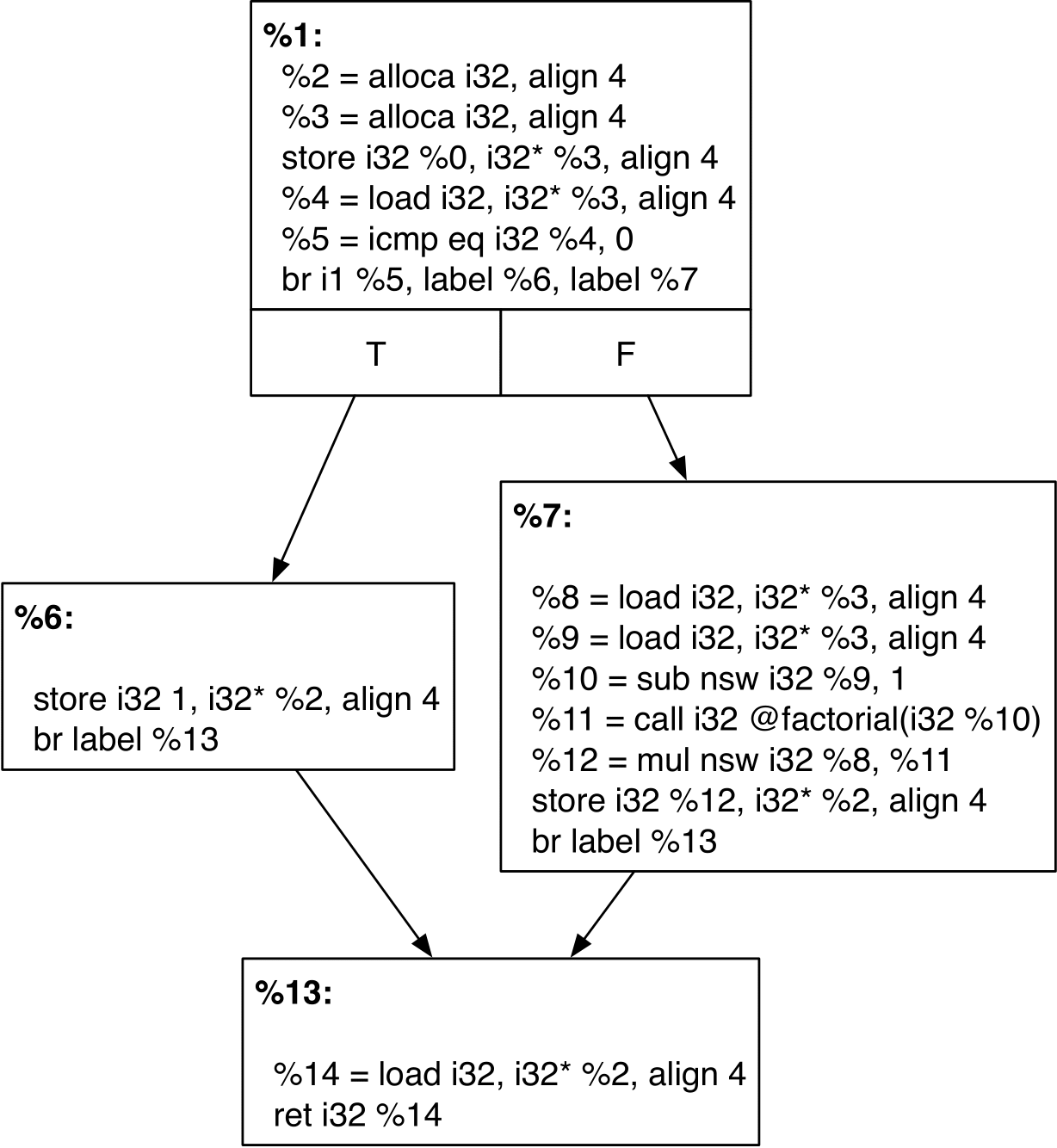
There are four basic blocks here.
Because this code is generated by clang it makes use of implicit identifiers (%0,%1, %2,…).
For example, %0 refers to the identifier that is the argument to the @factorial function, and %1 is the label of the entry block.
Note that our subset, LLVM--. requires that the entry basic block is unlabeled, enforcing that the control flow cannot accidentally jump there – this loses no generality because we can always have an empty instruction sequence in the first basic block.
Phi nodes#
LLVM programs are in so-called SSA form (short for static single-assignment form).
That is, each register, when declared, is initialized with a value and can never be changed subsequently.
Note that the load and store instructions perform loading from and storing to memory locations (the address may be in a register) and not registers.
This raises an issue: what if we want to assign a value to a register based on which branch we take in the program?
An example of this can be seen in the factorial example above where this problem is solved by allocating space on the stack, %2 which is written to in both branches %6 and %7, and which is read and returned at the end of the function.
A better solution to this problem is to use so-called phi nodes which do not use stack space.
A phi node is of the form phi ty [val_1, %block_1], [val_2, %block_2], ..., [val_n, %block_n] where ty is the type of the value produced by the phi node.
The labels %block_1, …, %block_n are the labels of all the basic blocks that can branch to the basic block where the phi node is in.
The result of the phi node is val_i if the basic block where the phi is in is reached by branching from %block_i.
All values val_1, …, val_n must be of type ty.
Warning
A valid, well-formed phi node must always specify a value for any basic block that can reach the block where it appears in.
Note that in some cases a malformed phi node with the wrong labels referenced can trigger a bug in some versions of clang that causes it to crash.
The following is the code for the factorial function adapted to use a phi node instead of stack space.
define i32 @factorial(i32) {
%2 = alloca i32
store i32 %0, ptr %2
%3 = load i32, ptr %2
%4 = icmp eq i32 %3, 0
br i1 %4, label %5, label %6
5:
br label %12
6:
%7 = load i32, ptr %2
%8 = load i32, ptr %2
%9 = sub nsw i32 %8, 1
%10 = call i32 @factorial(i32 %9)
%11 = mul nsw i32 %7, %10
br label %12
12:
%13 = phi i32 [1, %5], [%11, %6]
ret i32 %13
}
Note
In a valid LLVM program, implicit registers in a function must be named in-order, and without skipping any numbers.
That is, if the last declared implicit register is %10, the next implicit register declared must be %11, otherwise, LLVM would reject the program.
This is the reason why in the code above we have renamed registers compared to the original factorial example above.
In particular, in the code above %2 is what %3 was in the original factorial example above.
In the code above the returned value, register %12, is computed using a phi node.
The phi node assigns value of register %10 to register %12 if the program reaches label %11 by branching from the basic block labeled %6.
Otherwise, if the label %11 was reached by branching from the basic block labeled %5, register %12 is assigned 1.
The getelementptr (GEP) instruction#
LLVM uses the getelementptr instruction (briefly, GEP) to implement an architecture-independent way of computing addresses of subelements in aggregate data structures, such as structures or arrays.
One way to make sense of GEP is to study how C array and structs can be compiled to LLVM because C influenced the design of LLVM (and GEP in particular).
Consider the C program below:
struct Tuple {
int x;
int y;
};
int foo(struct Tuple* tuple) {
return tuple[2].y;
// Try: return tuple[0].y
// return tuple->y
}
int main (int argc, char ** argv) {
struct Tuple tuples [] = { {11, 22},
{33, 44},
{55, 66} };
return foo (tuples); // returns 66
}
This program declares a tuple structure, initializes an array of tuples and uses the function foo to access the y-component of the second (counting from zero) element of the array.
Assuming the file example.c contains this program, we can compile, execute, and inspect the result of this program using the following shell commands:
$ clang example.c
$ ./a.out
$ echo $?
66
The following listing shows how clang translates the definition of the tuple structure to LLVM and a possible translation for function foo.
Note that this listing differs from the actual compiler output in two ways: first, we use the name Tuple instead of struct.Tuple; second, we simplified the code for function foo in order to focus on the explanation of GEP.
We revisit the actual output at the end of this section.
%Tuple = type { i32, i32 }
define i32 @foo(ptr %tuple) {
%ptr = getelementptr inbounds %Tuple, ptr %tuple, i64 2, i32 1
%x = load i32, ptr %ptr
ret i32 %x
}
Observe the two last arguments to GEP: i64 2, i32 1.
They encode the path to the address of tuple[2].y in the memory.
First, we ask for the pointer to the memory where the second element of the array lives – that is i64 2.
Next, we need the pointer to the y-component of the tuple.
Counting from 0, it is the 1-st element of the Tuple structure.
Note that LLVM uses i32 for indexing into structures because it is highly unlikely for structures to contain more than \(2^{32}\) elements.
The following picture visualizes the layout of the memory for this example, illustrating where the %tuple and %ptr registers point to in this layout.
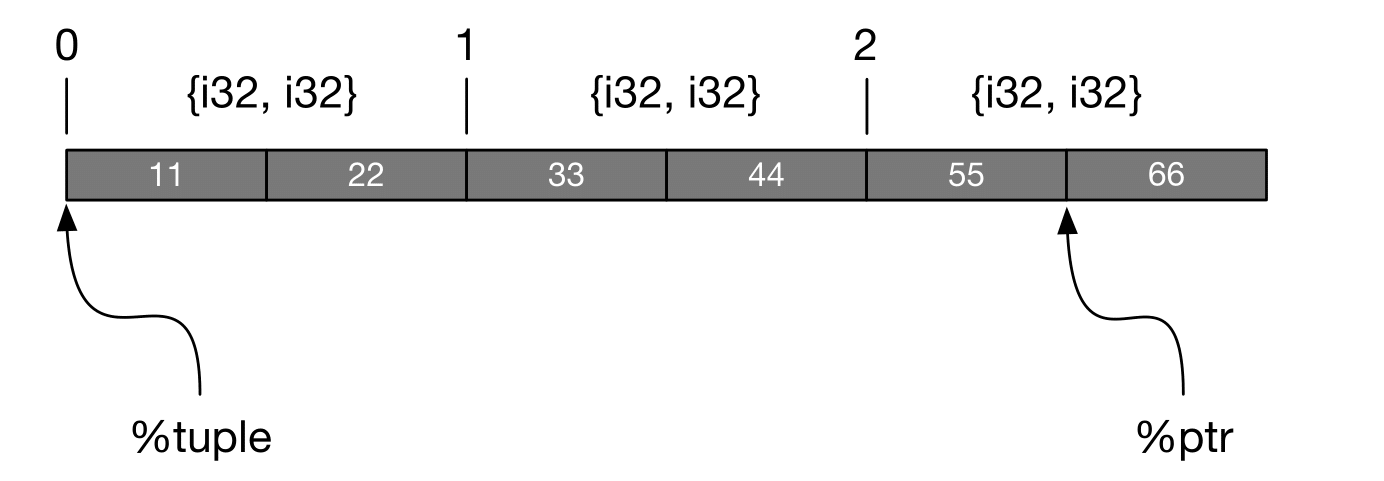
If we want to index into tuple[1].x, we should use the GEP instruction with the path i64 1, i32 0.
For tuple[0].y, it should be i64 0, i32 1, and so on.
There is a subtlety to GEP that is induced by the close relationship of arrays and pointers in C.
A reference to an array in C is just a pointer to the memory where the array starts, that is, the pointer to the zeroth element of the array.
This relationship is already apparent in the C declaration of the function foo where the tuple variable
has type struct Tuple*.
Therefore, GEP treats every pointer as a potential array.
This treatment implies that if we are given a pointer to an LLVM structure, and we want to access the n-th element of that structure, we need to treat that pointer as if it was a reference to a one-element array and we were accessing that one element at position 0 in that array.
This means that GEP paths for such accesses must have the form i64 0, i32 n.
Examining the actual output of the compiler#
Armed with the above observation, let us check out the actual code generated for @foo by clang (we ignore the specifics of inbounds and align annotations here):
%struct.Tuple = type { i32, i32 }
define i32 @foo(ptr) #0 {
%2 = alloca ptr, align 8
store ptr %0, ptr %2, align 8
%3 = load ptr, ptr %2, align 8
%4 = getelementptr inbounds
%struct.Tuple, ptr %3, i64 2
%5 = getelementptr inbounds
%struct.Tuple, ptr %4, i32 0, i32 1
%6 = load i32, ptr %5, align 4
ret i32 %6
}
The relevant parts here are the two GEPs.
They do the same computation as in the version we studied earlier, except that the task of computing the
address to tuple[2].y is split into two GEP operations.
The first one finds the offset to the start of the second element of the array.
That results in a pointer to a %struct.Tuple structure.
The second GEP finds the offset to the field at position 1 in that structure (once again, treating that pointer as a reference to a one-element array and hence prefixing the path with 0).
To experiment further with this example, one can compile the C code with clang -S -emit-llvm example.c, and modify the generated LLVM code for foo in an editor.
The modified .ll file can be compiled using the command clang example.ll.
A more involved GEP example#
We now consider a slightly more elaborate C program:
struct RT {
char A;
int B[10][20];
char C;
};
struct ST {
int X;
double Y;
struct RT Z;
};
int *foo(struct ST *s) {
return &s[1].Z.B[5][13];
}
The generated .ll file has the following code for foo and structure declarations.
%struct.ST = type { i32, double, %struct.RT }
%struct.RT = type { i8, [10 x [20 x i32]], i8 }
define ptr @foo(ptr) #0 {
%2 = alloca ptr, align 8
store ptr %0, ptr %2, align 8
%3 = load ptr, ptr %2, align 8
%4 = getelementptr inbounds %struct.ST, ptr %3, i64 1
%5 = getelementptr inbounds %struct.ST, ptr %4, i32 0, i32 2
%6 = getelementptr inbounds %struct.RT, ptr %5, i32 0, i32 1
%7 = getelementptr inbounds
[10 x [20 x i32]], ptr %6, i64 0, i64 5
%8 = getelementptr inbounds [20 x i32], ptr %7, i64 0, i64 13
ret ptr %8
}
We invite the reader to study the GEPs generated by the compiler and see whether they can match them to the source. One can ask an exercise question: can we rewrite this sequence of GEPs as one? The answer is yes. In fact, the code for this function could just as well be:
define ptr @foo(ptr %arg) #0 {
%x = getelementptr inbounds
%struct.ST, ptr %arg, i64 1, i32 2, i32 1, i64 5, i64 13
ret ptr %x
}
Here, the GEP path is the sequence of operands i64 1, i32 2, i32 1, i64 5, i64 13.
We can check if the two versions compute the same offsets with the help of the clang itself.
First, we expand our example as follows:
#include <stdio.h>
struct RT {
char A;
int B[10][20];
char C;
};
struct ST {
int X;
double Y;
struct RT Z;
};
int *foo(struct ST *s) {
return &s[1].Z.B[5][13];
}
int *bar(struct ST *s) {
return &s[1].Z.B[5][13];
}
int main (int argc, char** argv) {
int* a = foo (NULL);
int* b = bar (NULL);
printf ("foo: %p\nbar: %p\n", a, b);
return 0;
}
Observe that we have duplicated the code for foo in the function bar.
The main function calls each of these with the argument NULL.
The results a and b are the offsets from the NULL pointers.
This trick of using the NULL pointer argument effectively gives us the offsets calculated by each of the functions from the base argument provided to them.
We print the offsets in main (expecting the two to be the same).
Note that the program does not actually dereference anything – dereferencing an offset from a NULL pointer would
likely cause a segmentation fault at runtime – again, we are only computing the offsets.
If we compile and run this program, we get the following output:
$ clang example-orig.c
$ ./a.out
foo: 0x510
bar: 0x510
Here, 0x510 is the offset in hexadecimal (1296 in decimal).
Next, we can ask the compiler to generate the .ll file
$ clang -S -emit-llvm example.c
Now, we can go ahead and edit the code for @foo in example.ll.
Save, compile, and run it.
$ clang example.ll -o example-edited
$ ./example-edited
foo: 0x510
bar: 0x510
At this point, one can further play with the LLVM code for @foo.
For example, changing the last argument in the GEP path from 13 to 12 will yield a different offset.
Further reading#
For more on LLVM instructions and GEP, please consult the relevant pages on the LLVM website:
LLVM Reference Manual: https://www.llvm.org/docs/LangRef.html
The Often Misunderstood GEP Instruction: https://www.llvm.org/docs/GetElementPtr.html